

La révolution qui transforme les données, le pétrole des entreprises du XXIe Siècle
Imaginez que vous êtes l’unique bibliothécaire chargé d’organiser les millions de livres, d’archives et de documents éparpillés dans les 4 tours de la BnF … et de les rendre accessibles instantanément à tous. C’est exactement le défi auquel font face les entreprises modernes avec leurs données.
Depuis novembre 2022, La lumière est mise sur les gains potentiellement mirobolant de l’usage des outils d’intelligence artificielle et notamment des IA Générative. Mais ces gains ne seront probablement jamais atteints sans une finesse couplée à une qualité irréprochable des données pour entraîner ces modèles ou en retirer des usages pertinents.
Ainsi une révolution silencieuse se déroule dans les couloirs des entreprises pour atteindre le plein potentiel. Son nom ? Le Data Mesh. Cette approche, apparue en 2019, promet de transformer radicalement la façon dont sont gèrée cette montagne de données, qui croissent à un rythme vertigineux.
De l’ère préhistorique des data lake à l’iA : L’explosion de la quantité de données à exploiter
Pour comprendre l’ampleur du défi, un petit voyage dans le temps s’impose. En 1990, l’humanité générait environ 100 gigaoctets de données par jour. Autant dire qu’une simple clé USB aurait pu contenir la production mondiale d’une journée entière. Aujourd’hui, le paysage a radicalement changé. En 2025, nous produisons 181 zettabytes de données.1 Si les données de 1990 représentaient une goutte d’eau, celles de 2025 correspondraient au volume de tous les océans de la planète.
Cette croissance exponentielle, alimentée par l’intelligence artificielle, les réseaux sociaux et l’Internet des objets, place les entreprises face à un paradoxe : elles habitent en bordure d’un « lac de données », mais meurent « de soif » par manque d’informations exploitables.
Le cauchemar de la gestion centralisée des données.
Prenons l’exemple concret d’une grande banque française. Ses données sont éparpillées comme des pièces de puzzle géantes suivant la localisation de ses entités :
- les informations clients dans un système à Paris,
- les données de trading à Londres,
- les analyses de risque à Francfort,
- et les données marketing à Milan.
Chaque département fonctionne comme un silo hermétique, avec ses propres règles, ses propres formats et ses propres gardiens. Par ailleurs, pour leur besoin, chaque entité à peut-être fait des copies de donnée des autres silos ce qui augmente d’autant plus les capacités de stockage et donc des coûts d’infrastructure et de maintenance.
Une autre approche serait de centraliser toutes ces données dans ce que l’on appelle, les « data warehouse » ou les « data lake ». Ceci ressemblerait à s’y méprendre au système postal d’autrefois. Toutes les lettres doivent transiter par un bureau de tri central avant d’atteindre leur destination. Pratique quand on gère quelques milliers de courriers par jour, catastrophique quand on traite des milliards de transactions quotidiennes.
Les conséquences sont aussi prévisibles qu’un week-end de chasser-croisé au mois d’août : embouteillages de données, délais interminables pour obtenir une information, erreurs de manipulation, et équipes IT qui accumulent les heures supplémentaires.
Data Mesh : quand les données prennent leur indépendance
C’est ici qu’intervient le Data Mesh, concept théorisé par Zhamak Dehghani en 20192, qui révolutionne l’approche traditionnelle. Si le système centralisé ressemble à l’Ancien Régime du XVIIIe avec son pouvoir concentré à Versailles, le Data Mesh s’inspire davantage de la République fédérale allemande : chaque région (ou domaine métier) gère ses propres données de façon autonome, tout en respectant des règles communes.
Concrètement, plutôt que d’avoir une équipe IT centrale qui gère toutes les données de l’entreprise, le Data Mesh confie à chaque département la responsabilité de ses propres informations. Le service marketing devient propriétaire de ses données clients, le département financier maîtrise ses chiffres, et l’équipe logistique pilote ses flux. Chacun devient à la fois producteur et consommateur de données. Par la suite, on entreposerait toutes ces données dans un super marché où les consommateurs se baladeraient librement dans les rayons pour faire leur course selon leur besoin.
Cette approche repose sur quatre piliers fondamentaux :
- l’ownership par domaine métier : Comme vu précédemment, chaque métier devient propriétaire de ses données.

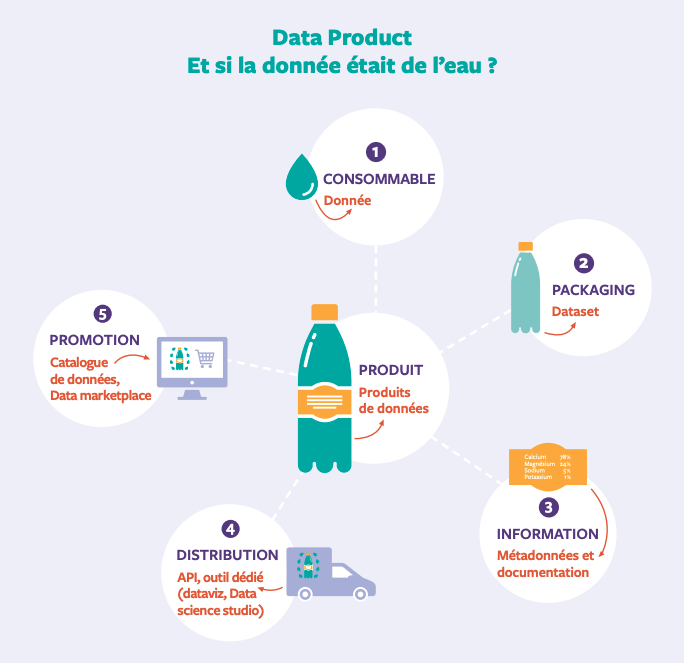
- Ensuite, les données sont construites comme un produit : elles sont vues comme de véritables produits avec leurs utilisateurs, leur qualité et leur cycle de vie. (Les produits mis en rayon dans le super marché et accessible librement)

- Troisièmement, l’infrastructure self-service : les équipes disposent d’outils leur permettant de gérer leurs données en autonomie. (L’achalandage des produit et la construction des rayonnages dans le super marché)
- Enfin, la gouvernance fédérée : des règles communes s’appliquent à tous, garantissant cohérence et sécurité.
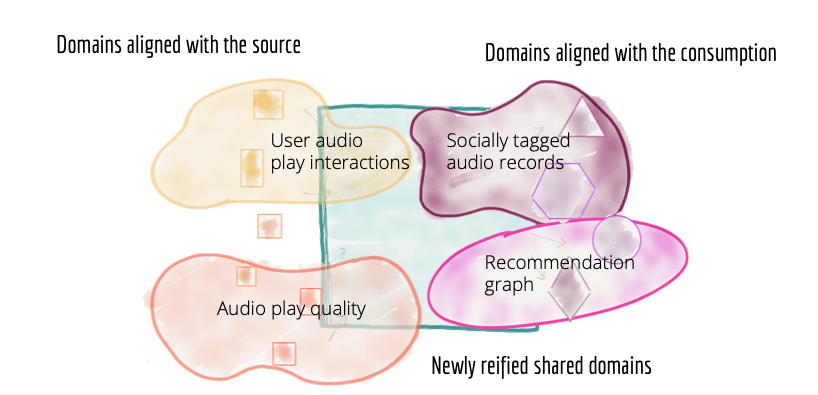
Un grand pouvoir implique de grandes responsabilités
Les avantages du Data Mesh sont nombreux.
- En premier lieu, l’agilité. Fini le temps où il fallait attendre trois mois pour obtenir un rapport. Chaque équipe peut désormais analyser ses données en temps réel.
- La qualité des données s’améliore également. Quand le service commercial est responsable de ses propres informations clients, il a tout intérêt à ce qu’elles soient exactes et à jour. C’est bien connu : « on prend mieux soin de ce qui nous appartient ».
- L’innovation s’accélère aussi. Les équipes peuvent expérimenter librement sans craindre d’impacter l’ensemble du système.
- Enfin, l‘adaptabilité. Contrairement aux systèmes monolithiques qui ressemblent à des pétroliers – puissants mais difficiles à manœuvrer -, le Data Mesh fonctionne comme une flotte de vedettes rapides, capables de changer de cap instantanément selon les besoins.
Les défis à relever
Attention, le Data Mesh n’est pas la potion magique. Sa mise en œuvre soulève des défis considérables, à commencer par les compétences. Transformer chaque équipe métier en spécialiste de la donnée revient à demander à des cuisiniers de devenir soudainement experts en chimie moléculaire. Cela nécessite une formation massive et un changement culturel profond.
Le défi technologique n’est pas en reste. Il faut mettre en place une infrastructure complexe qui permet à chaque domaine de fonctionner en autonomie tout en garantissant l’interopérabilité. Imaginez un réseau autoroutier où chaque région utilise ses propres panneaux tout en permettant à tous les conducteurs de se comprendre.
La gouvernance pose également question. Comment s’assurer que toutes ces équipes autonomes respectent les règles de sécurité et de conformité ? C’est l’éternel dilemme entre liberté et contrôle, entre innovation et stabilité.
Côté budget, l’investissement initial est considérable. Il faut former les équipes, adapter les outils, modifier les processus. Mais comme le pétrole à la fin du 19e siècle, l’investissement dans l’extraction, le transport et le raffinage a nécessité des sommes importantes pour arriver au boom économique des 30 glorieuses.
L’adoption
Le Data Mesh séduit déjà les banques, l’automobile, la logistique, l’énergie et la tech.3 Bien que Gartner évoque un risque d’obsolescence avant son “plateau”4, le concept pourrait évoluer plutôt que disparaître, intégrant des pratiques encore plus avancées.
À terme, le Data Mesh pourrait décentraliser la donnée dans les entreprises comme la Révolution française a décentralisé le pouvoir politique. Les données ne seraient plus un fardeau, mais un actif stratégique.
Vers un avenir décentralisé
Le Data Mesh n’est pas seulement une tendance technologique. C’est une réponse pragmatique à la complexité croissante et à l’explosion des volumes de données. Les entreprises qui adoptent cette approche auront un avantage décisif dans la transformation digitale, en exploitant leurs données comme jamais auparavant.
Sources :
1 Statista, « Volume of data/information created, captured, copied, and consumed worldwide from 2010 to 2025 », 2024
2 Zhamak Dehghani, « How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh« , 2019
3 VMware, « The Data Mesh Handbook: A Modern Data Architecture for Cloud-Native Organizations », 2024
4 Gartner Hype Cycle for Data Management, 2022
Franck ARSENE, Consultant Transformation Agile, Data & IA